

The twelve-factor app – aplikacja dwunastu czynników
Współcześnie, oprogramowanie jest powszechnie dostarczane jako usługa (aplikacja internetowa lub SaaS). The twelve-factor app jest metodologią, która pozwala na budowanie takich aplikacji w sposób skalowalny poziomo. Zawiera on doświadczenie i obserwacje z budowy szerokiej gamy aplikacji SaaS.
Aplikacja dwunastu czynników to metodologia, która służy do budowy aplikacji SaaS, które:
- Wykorzystują formaty deklaratywne do automatyzacji konfiguracji w celu zminimalizowania czasu i kosztu dla nowych deweloperów, którzy dołączają do projektu;
- W jasny sposób porozumiewają się z podstawowym systemem operacyjnym, oferując maksymalną możliwość przenoszenia pomiędzy środowiskami wykonawczymi;
- Są odpowiednie dla wdrożenia i nowoczesnych platform w chmurze, likwidując w ten sposób potrzebę administracji serwerów i systemów;
- Minimalizują rozbieżności pomiędzy rozwojem i produkcją, umożliwiając ciągłe wdrażanie dla maksymalnej elastyczności;
- Oraz które można skalować bez znaczących zmian w przygotowywaniu narzędzi, architekturze lub praktykach dotyczących wdrożeń.
Metodologia dwunastu czynników może być stosowana w przypadku aplikacji napisanych w dowolnym języku programowania, które wykorzystują dowolną kombinację usług tworzenia kopii zapasowych (baza danych, kolejka, pamięć podręczna itp.).
Spis treści
Kontekst
Tekst ten jest moim tłumaczeniem oryginalnego dokumentu The twelve-factor app.
Osoby tworzące niniejszy dokument były bezpośrednio zaangażowane w opracowanie i wdrożenie setek aplikacji, a także w sposób pośredni były świadkami rozwoju, pracy i skalowania setek tysięcy aplikacji dzięki pracy na platformie Heroku.
Niniejszy dokument scala całe nasze doświadczenie i obserwacje dotyczące szerokiej gamy aplikacji SaaS. To swego rodzaju triangulacja odnosząca się do idealnych praktyk w przypadku rozwoju aplikacji, która zwraca szczególną uwagę na dynamikę wzrostu organicznego aplikacji w czasie, dynamikę współpracy pomiędzy deweloperami pracującymi nad bazą kodu aplikacji, a także na unikanie kosztu pogorszenia się oprogramowania.
Nasza motywacja leży w zwiększeniu świadomości na temat pewnych problemów systemowych, które widzimy we wdrożeniach nowoczesnych aplikacji, a także w zapewnieniu wspólnego słownictwa dla dyskusji na temat tych problemów. Chcemy również zaoferować zestaw szerokich rozwiązań koncepcyjnych powyższych problemów z towarzyszącą terminologią. Książki Martina Fowlera: Patterns of Enterprise Application Architecture oraz Refactoring były inspiracją dla formatu.
Kto powinien przeczytać ten dokument?
Każdy deweloper, który zajmuje się budowaniem aplikacji działającymi jako usługa. Osoby pracujące na stanowisku ops engineer, devops, które wdrażają lub zarządzają takimi aplikacjami.
Dwanaście czynników
I. Codebase
Jedna baza kodu śledzona w systemie kontroli wersji, wiele wdrożeń
Aplikacja dwunastu czynników (ang. The twelve-factor app) zawsze śledzona jest w systemie kontroli wersji takim jak Git, Mercurial lub Subversion. Kopia bazy danych śledzenia wersji znana jest jako repozytorium kodu, często skracana do formy repo.
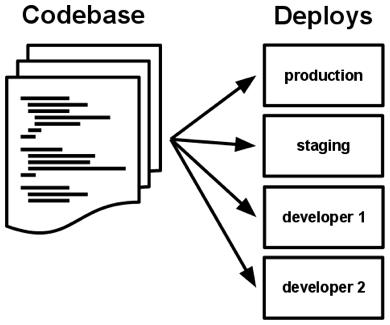
Baza kodu to dowolne pojedyncze repozytorium (w scentralizowanym systemie kontroli wersji takim jak np. Subversion) lub dowolny zestaw repozytoriów, które dzielą wspólny tzw. root commit (w decentralizowanym systemie kontroli wersji takim jak Git).
Pomiędzy aplikacją a bazą kodu istnieje korelacja jeden-do-jednego:
- Jeśli występuje wiele baz kodu, w takim przypadku nie mamy do czynienia z aplikacją, ale z systemem rozproszonym. Każdy element w systemie rozproszonym jest aplikacją, a każda z nich może indywidualnie spełniać zasady dwunastu czynników.
- Dzielenie jednego kodu przez wiele aplikacji narusza zasady dwunastu czynników. Rozwiązaniem jest tutaj rozłożenie dzielonego kodu na biblioteki, które mogą zostać włączone poprzez element zarządzający zależnościami.
Dla jednej aplikacji obowiązuje tylko jeden kod, ale wiele wdrożeń. Wdrożenie to uruchomione wystąpienie aplikacji. Zazwyczaj odnosi się do etapu produkcji i dotyczy również testowania aplikacji. Dodatkowo każdy deweloper ma kopię aplikacji, która działa w lokalnym środowisku wdrożeniowym, gdzie każda kwalifikuje się jako wdrożenie.
Baza kodu jest taka sama we wszystkich wdrożeniach, chociaż różne wersje mogą być aktywne w każdym wdrożeniu. Przykładowo, deweloper ma pewne zmiany, których nie wdrożył jeszcze do etapu testowania, a na tym etapie znajdują się zmiany, które nie zostały jeszcze wdrożone do produkcji. Wszystkie mają jednak tę samą bazę kodu, dzięki czemu można je zidentyfikować jako różne wdrożenia tej samej aplikacji.
II. Zależności
Wyraźnie określ i odizoluj zależności
Większość języków programowania oferuje systemy do tworzenia pakietów takie jak CPAN dla Perla lub Rubygems dla Ruby. Biblioteki zainstalowane za pośrednictwem takiego systemu mogą być instalowane w całym systemie (tzw. site packages) lub zawężone do katalogu, który zawiera aplikację (tzw. vendoring lub bundling).
Aplikacja dwunastu czynników nigdy nie opiera się na domniemanym istnieniu pakietów dla całego systemu. Deklaruje wszystkie zależności, wyczerpująco i dokładnie, poprzez manifest deklaracji zależności. Co więcej, wykorzystuje narzędzie do izolacji zależności podczas wykonania, aby upewnić się, że domniemane zależności nie „przeciekają” z otaczającego systemu. Pełna i wyraźna specyfikacja zależności zostaje jednolicie zastosowana zarówno do produkcji, jak i rozwoju.
Przykładowo, Gem Bundler dla Ruby oferuje format manifestu Gemfile dla deklaracji zależności oraz bundle exec dla izolacji. W języku Python istnieją dwa oddzielne narzędzia dla tych czynności — Pip jest wykorzystywany do deklaracji, a Virtualenv do izolacji. Nawet C posiada Autoconf dla deklaracji zależności, a linkowanie statyczne może zapewnić izolację zależności. Bez względu na zestaw narzędzi, należy zawsze razem używać deklaracji i izolacji zależności — tylko jeden element nie wystarczy do spełnienia „dwunastu czynników”.
III. Konfiguracja
Jedną z korzyści płynących z wyraźnej deklaracji zależności jest fakt, iż upraszcza ona konfigurację dla deweloperów nowych dla aplikacji. Nowy deweloper może sprawdzić kod bazy aplikacji na własnej maszynie wykorzystywanej do budowania aplikacji, przy czym wymaga do tego wyłącznie środowiska uruchomieniowego języka oraz elementu zarządzającego zależnościami, które zostały zainstalowane jako niezbędne elementy. Deweloper będzie mógł skonfigurować wszystko, co jest potrzebne do uruchomienia kodu aplikacji za pomocą deterministycznego polecenia build command. Przykładowo, build command dla Ruby/Bundler to bundle install, podczas gdy dla Clojure/Leiningen to lein deps.
Aplikacje dwunastu czynników (ang. The twelve-factor app) nie opierają się na ukrytym istnieniu jakichkolwiek narzędzi systemowych. Przykłady obejmują zakup programu ImageMagic lub curl. Podczas gdy powyższe narzędzia mogą istnieć w wielu lub nawet w większości systemów, nie ma gwarancji, że będą one występować we wszystkich systemach, w których w przyszłości działać będą aplikacje, ani że wersje przyszłych systemów będą z aplikacją kompatybilne. Jeśli konieczne jest kupno narzędzia systemowego, powinno zostać ono dostarczone jako część aplikacji.
Przechowuj config w środowisku
Config aplikacji to wszystko to, co może różnić się pomiędzy wdrożeniami (testowanie, produkcja, środowisko deweloperskie itp.). Obejmuje:
- Połączenia do bazy danych, Memcached, i inne usługi tworzenia kopii zapasowych
- Dane uwierzytelniające do usług zewnętrznych takich jak Amazon S3 lub Twitter
- Wartości przed wdrożeniem takie jak nazwa kanoniczna hosta dla wdrożenia
Aplikacje niekiedy przechowują config jako stałe w kodzie. To naruszenie dwunastu czynników, które wymagają wyraźnego oddzielenia configu od kodu. Config zasadniczo różni się w różnych wdrożeniach — kod nie.
Sprawdzenie, czy konfiguracja aplikacji została prawidłowo uwzględniona w kodzie polega na sprawdzeniu, czy baza kodu może zostać otwartym oprogramowaniem w dowolnym momencie, bez utraty żadnych danych uwierzytelniających.
Należy wziąć pod uwagę, że ta definicja słowa config nie uwzględnia wewnętrznej konfiguracji kodu takiej jak config/routes.rb w Rails lub sposobu, w jaki moduły kodu w Spring są połączone. Ten rodzaj konfiguracji nie różni się pomiędzy wdrożeniami — w ten sposób najlepiej zachowuje się w kodzie.
Innym podejściem do konfiguracji jest korzystanie z plików konfiguracyjnych, które nie są objęte w kontroli wersji, takie jak config/database.yml w Rails. To ogromna poprawa w wykorzystaniu stałych, które nie są uwzględnione w repozytorium kodu, ale podejście to nadal ma słabe strony: łatwo przez przypadek uwzględnić plik konfiguracji w repozytorium; istnieje tendencja polegająca na tym, że pliki konfiguracji są rozrzucone po różnych miejscach i w różnych formatach, przez co trudno jest zobaczyć i zarządzać całą konfiguracją w jednym miejscu. Dodatkowo wspomniane formaty często są określone dla danego języka lub struktury.
Aplikacja dwunastu czynników przechowuje config w zmiennych środowiskowych. Zmienne środowiskowe łatwo zmienić pomiędzy wdrożeniami bez zmiany jakiegokolwiek kodu. W przeciwieństwie do plików konfiguracji, istnieje mała szansa, że przypadkowo zostaną one uwzględnione w repozytorium kodu. W przeciwieństwie do niestandardowych plików konfiguracji lub innych mechanizmów konfiguracji takich jak Java System Properties są normami niezależnymi od języka czy systemu operacyjnego.
IV. Usługa tworzenia kopii zapasowej
Innym aspektem zarządzania konfiguracją jest grupowanie. Niekiedy aplikacje scalają config w nazwane grupy (często zwane „środowiskami„), których nazwy nadawane są po określonym wdrożeniu, np. środowiska development, test, i production w Rails. Metoda ta nie skaluje się w łatwy sposób: kiedy tworzonych jest więcej wdrożeń aplikacji, konieczne jest utworzenie nowych nazw środowisk takich jak staging lub qa. W czasie, gdy projekt się rozwija, deweloperzy mogą dodać własne specjalne środowiska, np. joes-staging, co skutkuje eksplozją kombinatoryczną w konfiguracji, przez co zarządzanie wdrożeniami aplikacji jest „kruche”.
W aplikacji dwunastu czynników (ang. The twelve-factor app) zmienne środowiskowe pełnią funkcję precyzyjnych kontrolerów, a każda zmienna jest w pełni ortogonalna w stosunku do innej. W aplikacji dwunastu czynników zmienne nigdy nie są razem zgrupowane jako „środowiska”, ale zamiast tego samodzielnie zarządzają każdym wdrożeniem. Model ten łatwo się skaluje — aplikacja naturalnie rozwija się na więcej wdrożeń w czasie.
Traktuj usługi tworzenia kopii zapasowych jako dołączone zasoby
Usługa tworzenia kopii zapasowych to dowolna usługa, którą aplikacja używa w sieci jako część normalnej pracy. Przykłady obejmują magazyny danych (takie jak MySQL lub CouchDB), a także systemy wiadomości lub kolejkowania np. RabbitMQ lub Beanstalkd), usługi SMTP dla wiadomości wychodzących (np. Postfix), i systemy pamięci podręcznej (takie jak Memcached).
Usługi tworzenia kopii zapasowych jak np. baza danych są zarządzane w sposób tradycyjny przez tych samych administratorów systemów, co środowisko uruchomieniowe dla wdrożenia aplikacji. Oprócz tych lokalnie zarządzanych usług, aplikacje mogą posiadać również usługi dostarczane i zarządzane przez strony trzecie. Przykłady obejmują usługi SMTP (takie jak Postmark), systemy zbierające metryki (np. New Relic lub Loggly), usługi dotyczące danych binarnych (np. Amazon S3), a nawet usługi z dostępem do API dla klientów (takie Twitter, Google Maps, czy Last.fm).
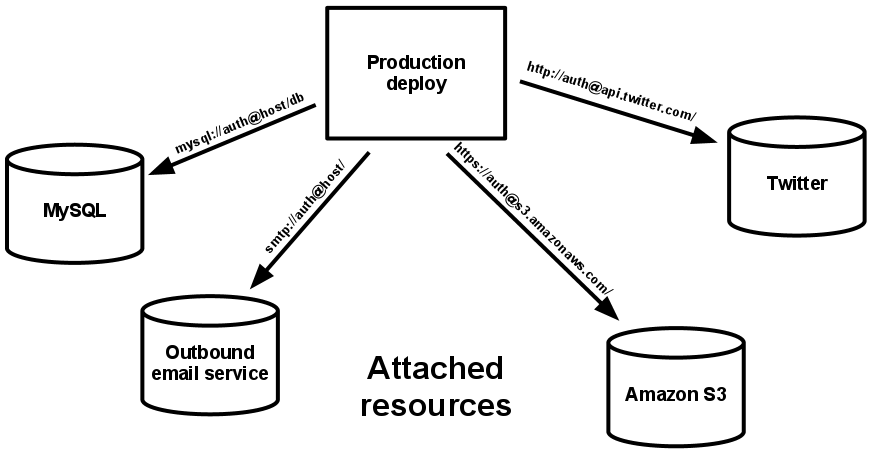
Kod aplikacji dwunastu czynników nie rozróżnia usług lokalnych i usług osób trzecich. Dla aplikacji powyższe elementy to dołączone zasoby, do których dostęp można uzyskać za pośrednictwem adresu URL lub innego lokalizatora/danych uwierzytelniających przechowywanych w config. Wdrożenie aplikacji dwunastu czynników powinno mieć możliwość zastąpienia lokalnej bazy danych MySQL jedną z baz zarządzanych przez stronę trzecią (np. Amazon RDS) bez jakichkolwiek zmian w kodzie aplikacji. Podobnie ma się rzecz z serwerem lokalnym SMTP — powinna być możliwość zastąpienia go usługą SMTP (np. Postmark) strony trzeciej bez zmiany kodu. W obu przypadkach należy zmienić jedynie uchwyt zasobu w config.
Każda wyraźna usługa tworzenia kopii zapasowych to zasób. Przykładowo, baza danych MySQL jest zasobem; dwie bazy danych MySQL (używane do dzielenia na poziomie warstwy aplikacji) kwalifikują się jako dwa odrębne zasoby. Aplikacja dwunastu czynników traktuje te bazy jako dołączone zasoby, które wskazują na luźne powiązanie z wdrożeniem, do którego są dołączone.
Zasoby mogą być dobrowolnie dołączane i odłączane do wdrożeń. Przykładowo, jeśli baza danych aplikacji nie zachowuje się prawidłowo ze względu na problem sprzętowy, administrator aplikacji może przyśpieszyć nowy serwer bazy danych, który został przywrócony z niedawnej kopii zapasowej. Obecna produkcyjna baza danych może zostać odłączona, a nowa dołączona — a wszystko to bez zmian w kodzie.
V. Buduj. Wdrażaj. Uruchamiaj.
Wyraźnie oddziel etapy budowy i uruchomienia
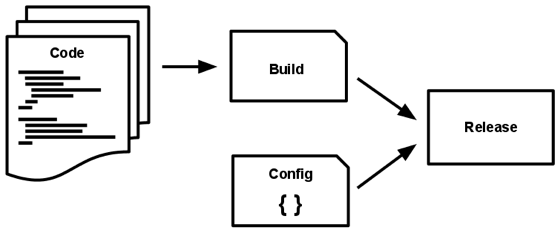
Baza kodu zostaje zmieniona we wdrożenie (które nie jest związane z rozwojem) w ramach trzech etapów:
- Etap budowy to swego rodzaju przekształcenie, które konwertuje repozytorium kodu do pakietu wykonywalnego znanego jako build. Używając wersji kodu przy zmianie (commit) określonej przez proces wdrażania, etap budowy pobiera i dostarcza zależności i kompiluje pliki binarne i zasoby.
- Etap wydania zabiera build stworzony podczas etapu budowy i łączy go z aktualnym config wdrożenia. Powstałe w tym skutku wydanie zawiera zarówno build, jak i config i jest gotowe do natychmiastowego wdrożenia w środowisku wykonawczym.
- Etap uruchamiania uruchamia aplikację w środowisku wykonawczym, poprzez uruchomienie niektórych procesów aplikacji względem wybranej wersji.
Aplikacja dwunastu czynników wykorzystuje wyraźne rozdzielanie etapu budowy, wydania i uruchomienia. Nie jest, przykładowo, możliwe wprowadzenie zmian do kodu na etapie uruchamiania, ponieważ nie ma sposobu na propagowanie zmian z powrotem na etap budowy.
Narzędzia wdrożeniowe zwykle oferują narzędzia do zarządzania wersją, a przede wszystkim możliwość przywrócenia do poprzedniej wersji. Na przykład narzędzie wdrożeniowe Capistrano przechowuje wersje w podkatalogu o nazwie releases, gdzie aktualna wersja jest łączem symbolicznym do katalogu bieżącej wersji. Polecenie rollback ułatwia powrót do poprzedniej wersji.
Każde wydanie powinno zawsze posiadać unikatowe ID, np. znacznik czasu wydania (np. 2011-04-06-20:32:17) lub liczbę rosnącą (np. v100). Jakakolwiek zmiana musi tworzyć nowe wydanie.
Deweloperzy aplikacji inicjują buildy zawsze wtedy, kiedy wdrożony jest nowy kod. Wykonanie środowiska uruchomieniowego może natomiast odbywać się automatycznie w przypadkach np. restartu serwera lub restartu uszkodzonego procesu za pomocą elementu zarządzającego procesami. W związku z tym, etap uruchomienia powinien składać się możliwie z niewielkiej liczby kroków, ponieważ problemy, które uniemożliwiają uruchamianie aplikacji mogą powodować awarię w środku nocy, kiedy akurat nie ma dostępnego dewelopera. Etap budowy może być bardziej złożony, ponieważ błędy dla dewelopera, który zajmuje się wdrożeniem, zawsze znajdują się na pierwszym planie.
VI. Procesy
Wykonuj aplikację jako jeden (lub więcej) proces bezstanowy
Aplikacja jest wykonywana w środowisku wykonawczym jako jeden (lub więcej) proces.
W najprostszym przypadku kod jest samodzielnym skryptem, a środowiskiem wykonawczym jest lokalny laptop dewelopera z zainstalowanym środowiskiem uruchomieniowym języka. Proces zostaje uruchomiony za pośrednictwem wiersza polecenia (np. python my_script.py). Z drugiej strony wdrożenie produkcyjne wyszukanej aplikacji może wykorzystywać wiele rodzajów procesów utworzonych w zero lub wiele uruchomionych procesów.
Procesy aplikacji dwunastu czynników są bezstanowe i nie współdzielą zasobów. Jakiekolwiek dane, których nie należy usuwać, muszą być przechowywane w stanowej usłudze tworzenia kopii zapasowej, zazwyczaj w bazie danych.
Obszar pamięci lub system plików procesu może służyć jako krótka pamięć podręczna o pojedynczej transakcji. Przykładowo: pobieranie dużego pliku, działanie na nim i przechowywanie wyników operacji w bazie danych. Aplikacja dwunastu czynników (ang. The twelve-factor app) nigdy nie zakłada, że jakiekolwiek elementy znajdujące się w pamięci podręcznej lub na dysku będą dostępne na żądanie w przyszłości lub dla przyszłego zadania — biorąc pod uwagę działanie wielu procesów każdego rodzaju, istnieje duża szansa, że przyszłe żądanie będzie obsługiwane przez inny proces. Nawet wtedy, gdy działa tylko jeden proces, restart (wywołany przez wdrożenie kodu, zmianę konfiguracji lub przeniesienie procesu do innej lokalizacji fizycznej przez środowisko wykonawcze) zazwyczaj zlikwiduje wszystkie dane lokalne (np. pamięć i system plików).
Narzędzia do tworzenia pakietów zasobów (np. Jammit lub django-compressor) używają systemu plików jako pamięci podręcznej dla skompilowanych zasobów. Aplikacja dwunastu czynników preferuje wykonanie powyższego zadania poprzez kompilację w trakcie etapu budowy, a nie w środowisku uruchomieniowym.
Niektóre systemy sieciowe opierają się na tzw. „lepkich sesjach” — oznacza to, że dane sesji użytkownika zostają przechwycone w pamięci procesu aplikacji i oczekują przekierowania przyszłych żądań od tego samego odwiedzającego do tego samego procesu. „Lepkie sesje” naruszają zasady dwunastu czynników. Nigdy nie powinno się ich stosować. Dane o stanie sesji są dobrym kandydatem do magazynu danych, który oferuje czas wygasania, np. Memcached lub Redis.
VII. Wiązanie portów
Eksportuj usługi poprzez wiązanie portów
Aplikacje sieci Web niekiedy wykonywane są w kontenerze serwera webowego. Na przykład aplikacje PHP mogą działać jako moduły wewnątrz Apache HTTPD lub aplikacje Java mogą działać wewnątrz Tomcat.
Aplikacja dwunastu czynników jest całkowicie samowystarczalna i nie polega na wstrzykiwaniu środowiska uruchomieniowego serwera sieciowego do środowiska wykonawczego w celu utworzenia usługi z bezpośrednim dostępem do sieci. Aplikacja sieciowa eksportuje HTTP jako usługę poprzez powiązanie do portu oraz nasłuchiwanie żądań do niego przychodzących.
W lokalnym środowisku wdrożeniowym, deweloper odwiedza adres URL usługi, np. http://localhost:5000/, w celu uzyskania dostępu do usługi wyeksportowanej przez aplikację. Podczas wdrażania warstwa przekierowująca obsługuje żądania od publicznej nazwy hosta do procesów sieciowych związanych portem.
Zazwyczaj czynność ta realizowana jest poprzez użycie deklaracji zależności w celu dodania biblioteki serwera sieciowego do aplikacji, np. Tornado dla Pythona, Thin dla Ruby, albo Jetty dla Java i innych języków opartych o JVM. Dzieje się to całkowicie w przestrzeni użytkownika, czyli wewnątrz kodu aplikacji. Kontrakt ze środowiskiem wykonawczym wiąże port do żądań serwera.
HTTP nie jest jedyną usługą, którą można eksportować poprzez wiązanie portów. Prawie każdy rodzaj oprogramowania serwera można uruchomić poprzez wiązanie procesu do portu i oczekiwanie na przychodzące żądanie. Przykłady obejmują ejabberd (czyli XMPP), oraz Redis (czyli protokół Redis).
Należy również zauważyć, że podejście polegające na wiązaniu portów oznacza, że aplikacja może stać się usługą tworzenia kopii zapasowych dla innej aplikacji poprzez zapewnienie adresu URL do aplikacji tworzącej kopię zapasową jako uchwyt zasobu w konfiguracji dla aplikacji zużywającej.
VIII. Współbieżność
Skaluj poprzez model procesów
Każdy program komputerowy po uruchomieniu jest reprezentowany przez jeden proces lub więcej. Aplikacje sieci Web przyjęły różne formy realizacji procesów. Przykładowo procesy PHP działają jako procesy podrzędne Apache. Uruchamiane są na żądanie zgodnie z objętością żądania. Procesy Java wykorzystują odwrotne podejście. JVM zapewnia jeden ogromny proces, który rezerwuje ogromny blok zasobów systemu (CPU i pamięć) podczas uruchomienia, natomiast współbieżność zarządzana jest wewnętrznie poprzez wątki. W oby przypadkach uruchomiony proces (lub procesy) są tylko minimalnie widoczne dla deweloperów aplikacji.
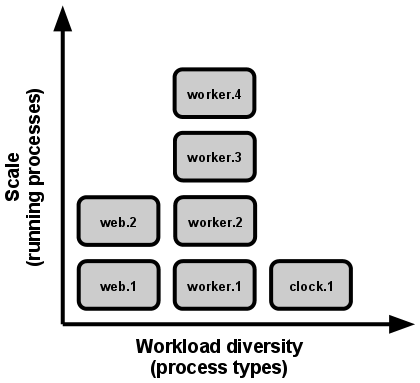
W aplikacji dwunastu czynników (ang. The twelve-factor app) procesy są obywatelem pierwszej kategorii. Procesy w aplikacji dwunastu czynników przyjmują silne sygnały z modelu procesów systemu Unix dla uruchamiania demonów usług. Za pomocą powyższego modelu deweloper może zaprojektować aplikację w ten sposób, aby ta mogła obsługiwać zróżnicowane obciążenie pracy poprzez przypisanie każdego rodzaju pracy do rodzaju procesu. Przykładowo, żądania HTTP mogą być obsługiwane przez proces sieciowy, a długotrwałe zadania w tle obsługiwane przez proces roboczy.
Powyższe nie wyklucza faktu, że poszczególne procesy mogą obsługiwać własne wewnętrzne multipleksowanie za pośrednictwem wątków wewnątrz VM środowiska uruchomieniowego lub modelu „async/evented”, który można znaleźć w narzędziach takich jak EventMachine, Twisted, czy Node.js. Indywidualna VM może jednak się rozrosnąć (skalowanie wertykalne), dlatego aplikacja musi mieć możliwość łączenia licznych procesów uruchomionych na wielu maszynach fizycznych.
Model procesów naprawdę „nabiera rumieńców”, kiedy mówimy o skalowaniu. Procesy aplikacji dwunastu czynników nie współdzielą zasobów i podlegają partycjonowaniu poziomemu — oznacza to, że dodanie dodatkowej współbieżności to prosta i niezawodna czynność. Szereg rodzajów procesów oraz liczba procesów każdego rodzaju nazywa się formacją procesów.
Procesy aplikacji dwunastu czynników (ang. The twelve-factor app) nie powinny nigdy „demonizować” lub zapisywać plików PID. Zamiast tego polegają na elemencie zarządzającym procesami systemu operacyjnego (jak np. Upstart, systemd, dystrybuowany menedżer procesów na platformie w chmurze lub np. narzędzie Forman w rozwoju) w celu zarządzania strumieniami wyjściowymi, reagowania na procesy, które uległy awarii, a także w celu obsługi ponownych uruchomień i zamknięć inicjowanych przez użytkownika.
IX. Łatwość rozporządzania aplikacją
Maksymalizuj niezawodność aplikacji dzięki szybkiemu uruchamianiu i łagodnemu zamknięciu
Procesami aplikacji dwunastu czynników można rozporządzać, co oznacza że można je uruchomić lub zatrzymać w ciągu krótkiej chwili. Umożliwia to szybkie, elastyczne skalowanie, natychmiastowe wdrożenie kodu lub zmiany konfiguracji, a także niezawodność wdrożeń produkcyjnych.
Procesy powinny dążyć do tego, aby minimalizować czas uruchamiania. Idealnie byłoby, aby proces trwał kilka sekund od czasu wykonania polecenia uruchomienia do momentu, aż proces jest gotowy do odbierania żądań lub zadań. Krótki czas uruchomienia zapewnia większą elastyczność dla procesu wydania i skalowania. Pomaga również w niezawodności aplikacji, ponieważ element zarządzający procesami może w łatwy sposób przenosić procesy do nowej maszyny fizycznej, kiedy jest to uzasadnione.
Procesy zostają łagodnie zamknięte w momencie, kiedy otrzymują sygnał SIGTERM z elementu zarządzającego procesami. W przypadku procesu sieci web łagodne zamknięcie osiąga się poprzez zaprzestanie nasłuchiwania portu serwera (i tym samym odmawianie nowych żądań), pozwalając jakimkolwiek bieżącym żądaniom na zakończenie, a następnie poprzez wyjście. Co niezwykle ważne w tym modelu to fakt, że żądania HTTP są krótkie (nie trwają dłużej niż kilka sekund), a w przypadku długiego sondowania, klient powinien bezproblemowo spróbować połączyć się w momencie, kiedy połączenie zostało utracone.
Dla procesu roboczego łagodne zamknięcie osiąga się poprzez przywrócenie bieżącego zadania do kolejki pracy. Przykładowo w RabbitMQ proces roboczy może wysłać NACK; w Beanstalkd zadanie jest automatycznie zwrócone do kolejki zawsze wtedy, kiedy proces roboczy zostaje rozłączony. Systemy oparte o blokady, np. Delayed Job muszą zwolnić blokadę rekordzie zadań. W niniejszym modelu ważny jest fakt, że wszystkie zadania są współużytkowane, co zazwyczaj osiąga się np. sprawienie, że operacja jest idempotentna.
Procesy powinny być również odporne na nagłą śmierć w przypadku awarii sprzętu bazowego. Chociaż jest to znacznie mniej powszechne niż łagodne zamknięcie z SIGTERM, może jednak się zdarzyć. Polecane podejście to użycie solidnego backendu kolejkowania, jak np. Beanstalkd, które zwraca zadania do kolejki, kiedy klient rozłącza się lub kiedy zostaje przekroczony limit czasu. Tak czy inaczej, aplikacja dwunastu czynników została zaprojektowana tak, aby obsługiwać nieoczekiwane, gwałtowne zakończenia procesów. Budowa typu crash-only doprowadza powyższy koncept do końca.
X. Parzystość dev/prod
Utrzymuj rozwój, staging i produkcję jako możliwie najbardziej zbliżone do siebie elementy
Z historycznego punktu widzenia pomiędzy rozwojem (deweloper wprowadzający żywe poprawki do lokalnego wdrożenia aplikacji) a produkcją (uruchomione wdrożenie aplikacji, do którego dostęp mają użytkownicy końcowi) istniały znaczne przerwy. Przerwy te objawiają się w trzech obszarach:
- Przerwa czasowa: deweloper może pracować nad kodem, który zajmuje wiele dni, tygodni, a nawet miesięcy zanim wejdzie w etap produkcji.
- Przerwa w personelu: deweloperzy piszą kod, osoby pracujące jako ops engineers wdrażają go.
- Przerwa w narzędziach: deweloperzy mogą używać stosów takich jak Nginx, SQLite, oraz OS X, podczas gdy wdrożenie produkcyjne używa Apache, MySQL i Linuxa.
Aplikacja dwunastu czynników (ang. The twelve-factor app) została zaprojektowana do ciągłego wdrażania poprzez utrzymywanie małego odstępu pomiędzy przerwami rozwoju i produkcji. Patrząc na trzy przerwy opisane powyżej:
- Utrzymuj niewielkie przerwy: deweloper może napisać kod i wdrożyć kilka godzin lub nawet kilka minut później.
- Sprawy, by przerwa w personelu była niewielka: deweloperzy, którzy piszą kod są ściśle zaangażowani w jego wdrażanie i obserwują zachowanie kodu w produkcji.
- Utrzymuj małą przerwę w narzędziach: spraw, aby rozwój i produkcja były możliwie najbardziej zbliżone.
Podsumowując powyższe w tabeli:
| Tradycyjna aplikacja | Aplikacja dwunastu czynników | |
| Czas pomiędzy wdrożeniami | Tygodnie | Godziny |
| Autorzy kodu vs osoby wdrażające kod | Różne osoby | Te same osoby |
| Środowiska deweloperskie i produkcyjne | Rozbieżne | Tak zbliżone, jak to możliwe |
Usługi tworzenia kopii zapasowych takie jak baza danych aplikacji, system kolejkowania lub pamięć podręczna to jeden z obszarów, gdzie parzystość dev/prod ma duże znaczenie. Wiele języków oferuje biblioteki, które upraszczają dostęp do usługi tworzenia kopii zapasowych, w tym adaptery dla usług różnego rodzaju. Niektóre z przykładów znajdują się poniżej.
| Rodzaj | Język | Biblioteka | Adaptery |
| Baza danych | Ruby/Rails | ActiveRecord | MySQL, PostgreSQL, SQLite |
| Kolejka | Python/Django | Celery | RabbitMQ, Beanstalkd, Redis |
| Cache | Ruby/Rails | ActiveSupport::Cache | Pamięć, system plików, Memcached |
Dla deweloperów używanie lekkich usług tworzenia kopii zapasowych w środowiskach lokalnych niekiedy jest niezwykle atrakcyjne, podczas gdy bardziej poważne i niezawodne usługi tego typu będą wykorzystywane w produkcji. Przykładowo — używacie SQLite lokalnie i PostgreSQL w produkcji; lub pamięci procesów lokalnych dla przechwytywania w trakcie prac rozwojowych oraz Memchached w produkcji.
Deweloper aplikacji dwunastu czynników musi powstrzymać się od użycia różnych usług tworzenia kopii zapasowych pomiędzy rozwojem a produkcją, nawet jeśli adaptery teoretycznie odbiegają od różnic w usługach tworzenia kopii zapasowych. Różnice pomiędzy tymi usługami oznaczają, że nagle mogą pojawić się maleńkie niekompatybilności, które sprawią, że kod, który działał i przeszedł testy w rozwoju lub podczas etapu staging nie będę skuteczny podczas produkcji. Takie rodzaje błędów powodują tarcia, które hamują ciągłe wdrażanie. Koszt takiego tarcia i następującego w efekcie tłumienia ciągłego wdrażania jest niezwykle wysoki, jeśli weźmie się pod uwagę łączny okres istnienia aplikacji.
Lekkie usługi lokalne nie są już tak atrakcyjne jak kiedyś. Instalacja i uruchomienie nowoczesnych usług tworzenia kopii zapasowych takich jak Memcached, PostgreSQL i RabbitMQ nie jest trudne, ze względu na nowoczesny system tworzenia pakietów, jak np. Homebrew i apt-get. Alternatywnie, narzędzia deklaratywne, np. Chef i Puppet w połączeniu z lekkimi środowiskami wirtualnymi, jak np. Vagrant umożliwiają deweloperom na uruchomienie środowisk lokalnych, które są ściśle zbliżone do środowisk produkcyjnych. Koszt instalacji i korzystania z tych systemów jest niski w porównaniu do korzyści parytetu dev/prod i ciągłego wdrażania.
Adaptery do różnych usług tworzenia kopii zapasowych są nadal przydatne, ponieważ dzięki nim portowanie do nowych usługi tworzenia kopii zapasowych przebiega stosunkowo bezboleśnie. Jednak wszystkie wdrożenia aplikacji (środowiska wdrożeniowe, staging, produkcja) powinny używać tego samego rodzaju i wersji każdej usługi tworzenia kopii zapasowych.
XI. Dzienniki
Traktuj dzienniki jako strumienie zdarzeń
Dzienniki zapewniają wgląd w zachowanie działającej aplikacji. W środowiskach opartych o serwery, dzienniki często zapisywane są do pliku na dysku (plik dziennika), jest to jednak jedynie format wyjściowy.
Dzienniki są strumieniem łącznych zdarzeń ułożonych chronologiczne ze strumienia wyjściowego wszystkich uruchomionych procesów i usług tworzenia kopii zapasowych. W surowej formie dzienniki występują zazwyczaj w formacie tekstowym z tylko jednym zdarzeniem na wers (chociaż ślady wsteczne od wyjątków mogą obejmować wiele wersów). Dzienniki nie mają wyraźnego początku lub końca — pojawiają się nieprzerwanie podczas działania aplikacji.
Aplikacja dwunastu czynników (ang. The twelve-factor app) nigdy nie obejmuje routowania ani przechowywania strumienia wyjściowego. Nie powinna próbować zapisywać do plików dziennika lub nimi zarządzać. Zamiast tego każdy uruchomiony proces zapisuje się w strumieniu zdarzeń, niezbuforowany, do stdout. Podczas wdrożenia lokalnego deweloper będzie miał widok na strumień na przedzie terminalu, dzięki czemu będzie mógł obserwować zachowanie aplikacji.
We wdrożeniach testowych lub produkcyjnych, strumień każdego procesu zostanie przechwycony przez środowisko wykonawcze, zestawiony z wszystkimi innymi strumieniami z aplikacji, a następnie przekierowany do jednego lub więcej miejsca docelowego w celu wyświetlania i długotrwałej archiwizacji. Docelowe miejsca archiwizacyjne nie są widoczne ani konfigurowalne dla aplikacji, a zamiast tego są w pełni zarządzane przez środowisko wykonawcze. Dla tego celu dostępne są routery dziennika typu open source (np. Logplex i Fluent).
Strumień zdarzeń dla aplikacji może być kierowany do pliku lub obserwowany w końcowym fragmencie w terminalu w czasie rzeczywistym. Co ważniejsze, strumień może być przesyłany do systemu indeksowania i analizy dziennika takiego jak Splunk lub do systemu magazynowania danych o celach ogólnych, np.Hadoop/Hive. Powyższe systemy umożliwiają duże możliwości i elastyczność obserwacji zachowania aplikacji w czasie, w tym:
- znajdywania określonych wydarzeń w przeszłości.
- analizowania trendów na dużą skalę (np. żądania na minutę).
- aktywnego powiadamiania zgodnie z algorytmami heurystycznymi określonymi przez użytkownika (np. powiadomienie kiedy liczba błędów na minutę przekracza określony próg).
XII. Procesy administracyjne
Uruchamiaj zadania administracyjne/zarządzania jako jednorazowe procesy
Formacja procesów to szereg procesów wykorzystywanych do wykonywania regularnych zadań aplikacji (np. obsługi żądań sieciowych) podczas pracy. Deweloperzy będą często chcieli wykonywać jednorazowe zadania administracyjne lub zadania zarządzania aplikacji, na przykład:
- Uruchamianie migracji bazy danych (np.
manage.py migratew Django,rake db:migratew Rails). - Uruchamianie konsoli (zwanej również powłoką REPL) do uruchamiania dowolnego kodu lub porównania modelu aplikacji z aktywną bazą danych. Większość języków zapewnia REPL poprzez uruchomienie interpretatora bez żadnych argumentów (np.
pythonlubperl) lub w niektórych przypadkach istnieje oddzielne polecenie (np.irbdla Ruby,rails consoledla Rails). - Uruchamianie jednorazowych skryptów przekazanych do repozytorium aplikacji (np.
php scripts/fix_bad_records.php).
Jednorazowe procesy administracyjne powinny działać w identycznym środowisku jak regularne długotrwałe procesy aplikacji. Procesy te działają względem wersji, wykorzystując tę samą bazę kodu i config jak dowolny proces działający względem danej wersji. Kod administracyjny musi działać z kodem aplikacji, aby uniknąć problemów z synchronizacją.
Te same techniki izolacji zależności powinny być stosowane we wszystkich typach procesów. Przykładowo, jeśli proces sieci Web oparty o Ruby wykorzystuje polecenie bundle exec thin start, wtedy migracja bazy danych powinna używać bundle exec rake db:migrate. Tak samo, język Python korzystający z Virtualenv powinien używać polecenia bin/python dla uruchomienia zarówno serwera www Tornado jak i dowolnego procesu administracyjnego manage.py.
Dwanaście czynników (ang. The twelve-factor app) to metodologia, która zdecydowanie wspiera języki, które zapewniają powłokę REPL ootb, a także dzięki którym uruchomienie jednorazowych skryptów nie jest skomplikowane. W przypadku wdrożenia lokalnego, deweloperzy mogą wywołać jednorazowy proces administracyjny poprzez bezpośrednie polecenie shella wewnątrz katalogu projektowego aplikacji. W przypadku wdrożenia produkcyjnego, deweloperzy mogą używać ssh lub zdalnego mechanizmu wykonywania poleceń zapewnionego przez środowisko wykonawcze wdrożenia do uruchomienia takiego procesu.
Bądź na bieżąco

Zobacz inne nasze artykuły
Zobacz wszystkie artykuły
17 lipca 2023
Odsprzedaż nazwy domen. Na czym polega?
Czytaj dalejOdsprzedaż nazwy domen – jak to działa i dlaczego warto się tym zainteresować? Odkupienie i odsprzedaż nazw domen to popularna praktyka w świecie internetu. W artykule eksperckim dowiesz się, czym jest odsprzedaż nazw domen, dlaczego ludzie decydują się na tę formę inwestycji oraz jak przebiega cały proces. Poznasz również czynniki wpływające na wartość odsprzedawanej nazwy…
Adres IP. Co to jest i do czego służy adres IP?
Czytaj dalejAdres IP, czyli Internet Protocol, jest fundamentalnym elementem funkcjonowania internetu. To unikalny identyfikator przypisywany każdemu urządzeniu podłączonemu do sieci. Dzięki adresowi IP możliwa jest wymiana danych między urządzeniami oraz ich identyfikacja w sieci. Adres IP może być publiczny lub prywatny, a jego przydzielanie odbywa się poprzez różne instytucje. Ten artykuł ekspercki przedstawia różne aspekty adresów…

Adres URL. Co to jest, do czego służy i jak działa?
Czytaj dalejAdres URL (Uniform Resource Locator) to unikalny identyfikator, który wskazuje lokalizację zasobu w sieci internetowej. Jest to ciąg znaków, który umożliwia nam dotarcie do konkretnej strony internetowej, pliku, obrazka lub innego zasobu. Adres URL składa się z kilku elementów, takich jak protokół, domena i ścieżka, które razem określają dokładne miejsce, gdzie znajduje się dany zasób.…