

What is high availability of server or website?
Everyone who runs an online business should be familiar with this subject. And certainly he remembers it at the moment when his website or shop just doesn’t work. Then the business, colloquially speaking, lies and does not earn money. And yet breakdowns happen. Is it possible to avoid it somehow and how much can it cost?
When running an analog business, you have to counteract many unexpected problems. When you’re involved in wedding photography, you’ve got a few SLRs and cameras each. Running a transport company, you take care of a spare car, spare parts or a quick service with a mechanic. Some risks you take and others you can counteract. In the digital world it is exactly the same, which unfortunately you forget about or do not know.
What’s worse, the marketing slogans like “cloud always works, upload it to the server it won’t disappear” don’t help to understand the subject of availability.
It’s time to face the topic of Internet service availability, because as you can probably guess, they can also not work.
Spis treści
What is availability?
Availability is one of the basic measures that determines the degree of failure resistance of a system. Availability is the time during which a system or service operates without failure.
If we take 1 day as a unit of time and the availability of the system was 75%, it means that it has been providing services for 18 hours and not for the remaining 6 hours. When it comes to the availability of IT systems, the accepted availability class is also used.
| Unavailability | ||||||
|---|---|---|---|---|---|---|
| Availability | Class | Type | Yearly | Monthly | Weekly | Daily |
| 90% | 1 | Unmanaged | 36d 12h 34m 55,2s | 3h 1g 2m 54,6s | 16h 48m 0,0s | 2h 24m 0,0s |
| 99% | 2 | Managed | 3d 15h 39m 29,5s | 7h 18m 17,5s | 1h 40m 48,0s | 14m 24,0s |
| 99,9% | 3 | Well Managed | 8h 45m 57,0s | 43m 49,7s | 10m 4,8s | 1m 26,4s |
| 99,99% | 4 | Fault Tolerant | 52m 35,7s | 4m 23,0s | 1m 0,5s | 8,6s |
| 99,999% | 5 | High-Availability | 5m 15,6s | 26,3s | 6,0s | 0,9s |
| 99,9999% | 6 | Very-High-Availability | 31,6s | 2,6s | 0,6s | 0,1s |
| 99,99999% | 7 | Ultra-Availability | 3,2s | 0,3s | 0,1s | 0,0s |
The availability class really says how many nines there are. The larger the class, the more available the system is. Popular network services, hostings offer availability ranging from 90% to 99.9%. Of course the scale of availability is open, so nothing stands in the way of offering services with availability, e.g. 95%.
What is Service Level Agreement?
SLA, i.e. Service Level Agreement, is an agreement that specifies, among other things, the level of availability of services provided. Such an agreement may also contain clauses on contractual penalties for failure to meet the required availability. An example may be AWS cloud services.
| Usługa AWS | SLA | When the compensation | Amount of compensation |
|---|---|---|---|
| EC2 | 99,99% | Less than 99.99% but equal to or greater than 99.0% | 10% |
| Less than 99.0% but equal to or greater than 95.0% | 30% | ||
| Less than 95.0% | 100% | ||
| RDS | 99,95% | Less than 99.95% but equal to or greater than 99.0% | 10% |
| Less than 99.0% but equal to or greater than 95.0% | 25% | ||
| Less than 95.0% | 100% | ||
| S3 | 99,9% | Less than 99.9% but greater than or equal to 99.0% | 10% |
| Less than 99.0% but greater than or equal to 95.0% | 25% | ||
| Less than 95.0% | 100% |
Looking at the SLA in Amazon Web Services, it is important to remember that it is about the services they offer, not the virtual machine. The SLA for an EC2 service does not imply the availability of this server, but a service that allows it to be created and managed. This means that if the machine itself fails, you still have a service available to run a back-up server.
What availability is right for me?
“My website must always work”, “I’ve lost millions in 20 minutes of failure!” – how many times it’s been heard or read on the web. After all, each of us wants the highest possible availability of services. Remember that systems with 99.99% availability can cost a lot. So how to assess which availability will be appropriate?
First of all, start by analysing the risks associated with the unavailability of a particular service. Breakdowns like to appear in the least expected moment, e.g. during increased sales on Black Friday. The fact that a website or server has worked perfectly for the last few months does not necessarily mean that this will happen tomorrow.
Every business owner must ask himself the same question, for how long a given service may not work so that it is not dangerous? Perhaps if you run an online store selling one size of nails you won’t lose too much when it’s turned off for a few hours. It is different when we run, for example, a system monitoring the vital signs of a patient. Here, there can be no question of downtime in operation.
Once you have determined the maximum and acceptable unavailability for you, you can choose the right service to meet these requirements. High availability is not free and can cost a lot of money, so sometimes it’s worth taking the risk per frame.
How much can it cost me?
Definitely more than a single server or hosting. Guaranteed high availability, e.g. class 4 (monthly about 4 minutes of unavailability of the service), requires a properly developed infrastructure, including
- more servers, more network devices – the hardware likes to play tricks, so the machines should at least be duplicated,
- administrators working in shift mode – failures do not take time off and can occur even on holidays,
- appropriate software – the website itself must be prepared to work on multiple servers at the same time.
There are also backup Internet connections, the possibility of exchanging server components during its operation, backup power supply, monitoring, infrastructure testing and so on. There is a lot of it.
It will not be a great discovery to say that a website based on one server works as long as it doesn’t break down.
What’s going to break down? For example: hard drive, power or cooling. We can buy a more expensive server that has redundant power supplies and fans, and drives working in the arrays. This way we increase the availability of the server, but it is still one server that can be subject to other failures.
Let’s calculate the SLA and the costs
To illustrate how the price of the service can vary depending on the availability of servers, let’s count it for an example of an online store based on some popular CMS.
For simplicity, things like software, administrator response time, network availability and how the servers are set up in the data center will be omitted. Adding a second server to the infrastructure will not increase our availability if it is plugged into the same power source as the first one. A power failure will simply put both machines together.
The Internet shop operates on two servers: a web server and a server with a database. SLA for each of these machines is 99.5% per month, which gives us 3h 39m 8.7s of unavailability. Exactly! And what is the SLA for the whole?
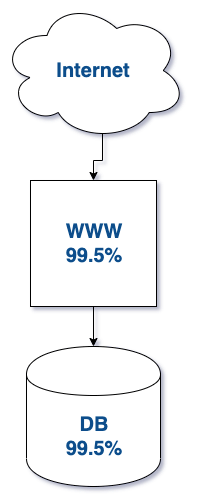
With two servers arranged in series, the whole system fails when it fails:
- Web server doesn’t work
- Database server does not work
- Both servers do not work
Mathematics here is absolute and SLA for such infrastructure is a multiplication of individual SLA of each of the servers.
SLA = 99,5% * 99,5% = 99%
| Server | Cost | SLA | Unavailability |
|---|---|---|---|
| WWW | 200$ | 99.5% | 3h 39m 8.7s |
| DB | 200$ | 99.5% | 3h 39m 8.7s |
| Total cost | Total SLA | Total unavailability | |
| 400$ | 99% | 7g 18m 17.5s |
Over 7 hours of unavailability of the service is practically one working day. Many online shops cannot afford such a downtime. Therefore, some redundancy would be useful.
To increase the availability of the entire store, we have added an additional web server and Loadbalancer, which will direct traffic to the working device. Loadbalancer can be a much weaker and therefore cheaper machine.
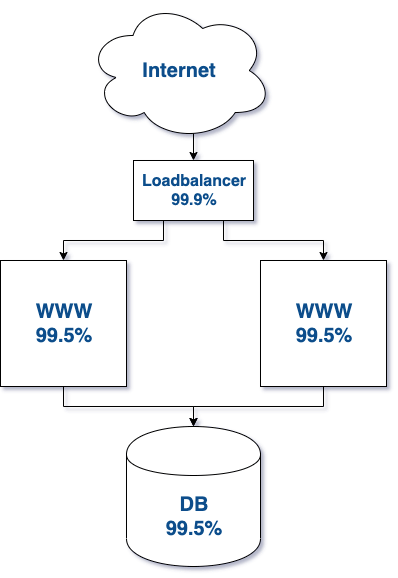
Let us now calculate the SLA for such infrastructure. We already have parallel web servers connected here. The formula for calculating the SLA for such infrastructure will look like this:
SLA = 0,999 * (1 - (1 - 0,995)2) * 0,995 = 99,4%
| Server | Cost | SLA | Unavailability |
|---|---|---|---|
| Loadbalancer | 100$ | 99.9% | 43m 49,7s |
| WWW | 200$ | 99.5% | 3h 39m 8.7s |
| WWW | 200$ | 99.5% | 3h 39m 8.7s |
| DB | 200$ | 99.5% | 3h 39m 8.7s |
| Total cost | Total SLA | Total unavailability | |
| 700$ | 99,4% | 4h 22m 58.5s |
Over 4 hours of unavailability is still a lot, but the incident is better than in the previous example. Looking at the architecture, we still have a few elements whose failure causes a big problem. We have one database and a loadbalancer, whose disabling will result in the lack of access to the other servers.
So let’s introduce redundancy at each level and see the SLA and the price of the infrastructure.
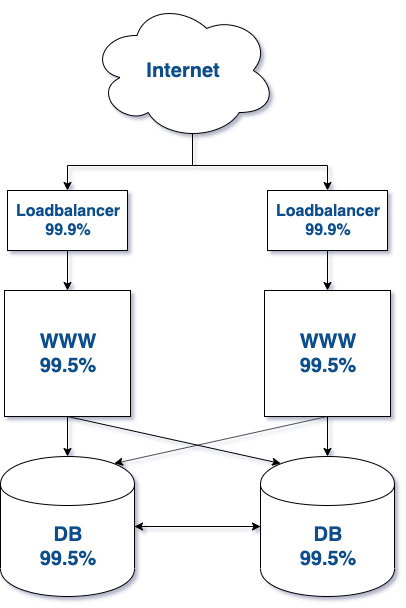
SLA = (1 - (1 - 0,999)2) * (1 - (1 - 0,995)2) * (1 - (1 - 0,995)2) = 99,99%
| Server | Cost | SLA | Unavailability |
|---|---|---|---|
| Loadbalancer | 100$ | 99.9% | 43m 49,7s |
| Loadbalancer | 100$ | 99.9% | 43m 49,7s |
| WWW | 200$ | 99.5% | 3h 39m 8.7s |
| WWW | 200$ | 99.5% | 3h 39m 8.7s |
| DB | 200$ | 99.5% | 3h 39m 8.7s |
| DB | 200$ | 99.5% | 3h 39m 8.7s |
| Total koszt | Total SLA | Total unavailability | |
| 1200$ | 99,99% | 4m 23,0s |
In this way, a satisfactorily high SLA was achieved. Unfortunately, the price is also high, almost two and a half times higher. And remember that this is only a simulation, which omits many elements such as administrative support, or the availability of the network itself.
Summary
When deciding on a solution with a specific availability, you should consider the real impact of every hour of downtime on your business. By running a small blog, we can choose a simple hosting, and by building a large web application for thousands of customers, we can choose redundant solutions.
We can also count on luck that one server will always work. Failures are like falling on a hard sidewalk – from a high height – they hurt.
Be up to date

Check other blog posts
See all blog posts
Why is it a good idea to split sites across different hosting accounts?
Read moreMultiple websites on one server is a threat that can have different faces. Find out what the most important ones are and see why you should split your sites on different hosting accounts. Powiązane wpisy: Compendium: how to secure your WordPress? Everything you have to keep in mind when creating an online store Useful plugins…

How do you get your website ready for Black Friday or more traffic?
Read moreToo much website traffic can be as disastrous as no traffic at all. A traffic disaster results in server overload. In such a situation, no one is able to use e.g. your online store’s offer, and you do not earn. Learn how to optimally prepare your website for increased traffic. Powiązane wpisy: Compendium: how to…

Password management or how not to lose your data
Read moreDo you have a bank account? Use the internet with your smartphone? Congratulations! Then you are on the brighter side of the power, where digital exclusion does not reach. But can you take care of the security of your data as effectively as you invite your friend for a beer via instant messenger? Powiązane wpisy:…